
Repairs That Do Not Restore

Before your program can find failures, it needs to stop creating them.
Most reliability programs begin in the wrong place and run out of steam before they reach the real world. They start at failure mode identification — what can go wrong with this equipment, and how do we detect it? This is a reasonable question if you are designing a new system. It is the wrong question if your running plant already has an active, daily process of damaging its own equipment.
The maintenance and reliability advice industry has conditioned us to look upstream: better analysis, better strategies, better training, better culture. What it has almost entirely ignored is execution – and the key fact that most industrial facilities are reliably introducing three categories of defects on schedule, at every maintenance event and in every operating shift — and calling the result a reliability problem. It is a self-inflicted wound. And it can’t be solved with more analysis.
This is the Maintenance Execution Gap – the subject of my forthcoming book. This blog is drawn from the opening. It describes the three defect sources you own, the specific mechanism by which maintenance work destroys the equipment it is supposed to restore, and the physics that make execution precision non-negotiable.
What Your Shift Log Is Not Telling You
On a Tuesday night shift at Crude Unit 2, Operations directed a pump swap — P-1105A to P-1105B — so Maintenance could isolate a leaking upstream valve. Standard procedure. The operator walked to P-1105B, opened what he believed was the discharge valve — it was the minimum-flow recirculation valve, already open — and started the pump. The discharge block valve was closed.
P-1105B ran for twenty-two minutes with the discharge block valve shut, circulating only through the minimum-flow line. Motor amps spiked briefly at start, then settled to a low, steady value — lower than normal because the pump was operating near shutoff, with almost no mass flow to carry heat away. The casing temperature rose. The seal chamber ran hot. Flush flow across the faces was inadequate for the condition, and the seal faces began to overheat and distress. The bearing oil slowly absorbed the heat migrating through the housing.
The operator noticed the lack of discharge flow, shut the pump down, and called the control room. The board operator logged it: “22:47 — Started P-1105B, no flow. Shut down. Returned to P-1105A.” No notification was written. No work order was generated. No one inspected P-1105B for damage from operating at shutoff. The seal faces were not checked for thermal distress. The bearing oil was not sampled for heat darkening or varnish.
Three months later, when P-1105B’s mechanical seal began to weep, no one connected it to that night. The faces had been overheated. The oil film had been compromised. Damage had been initiated, not completed. The event existed only in a handwritten shift log filed in a cabinet and never referenced again.
The operator was not negligent. He was unsupported. The system provided no startup checklist, no verified valve lineup procedure, no requirement to document abnormal rotating equipment events, and no trigger for post-incident inspection after a deadhead condition.
Most reliability engineering practice begins at failure mode identification: what can go wrong with this equipment, and how do we detect it?
When improving the reliability of a running plant, this is not the right starting point. The right starting point, with immediate effect is the maintenance and operations practices we are doing right now, every day, that make or break our equipment reliability.
Before spending another resource on analysis or PM optimization — stop damaging your own equipment. There are three defect sources you own. They are the most common, the least commonly addressed, and the most impactable levers available to you.
The Three Defect Sources You Own
The first defect source is operations-induced damage. The greatest opportunity for operations-introduced damage is during startup, shutdown, and transients, but off-spec operations can be impacting your equipment during every operating moment between maintenance actions.
This is the P-1105B deadhead event. Running pumps against closed valves. Operating compressors beyond surge limits. Thermal shock from rapid startups. Allowing process fluids to contaminate lubricants. Sustained off-BEP operation that loads bearings and seals beyond their design envelope for hours or days at a time. Triggering water hammer with rapid valve closure. Drawing vacuum on pump suctions during process upsets, cavitating impellers that should last decades in a matter of hours. Running equipment dry for sixty seconds during startup because nobody verified the flush line was open. Cycling motors through repeated starts during troubleshooting, accumulating winding damage that shows up as an inexplicable motor failure six months later.
Industry literature commonly attributes 25 to 40 percent of equipment failures to operational causes. The direction is consistent: operations is a primary failure driver that most reliability programs treat as outside their scope.
The second defect source is maintenance-induced damage. Winston Ledet’s research at DuPont, conducted with MIT’s Mark Paich, found that 84 percent of equipment defects originate from work practices that fail to provide the precision care equipment requires. Twelve percent come from normal wear. Four percent from aging. Analysis of Boeing in-flight engine shutdowns found installation issues were a contributing factor in 69 percent of events. In nuclear power, 27 percent of maintenance-related events were attributed to maintenance performed incorrectly, and another 19 percent to procedure deficiencies.
The pattern is consistent across industries: the people attempting to prevent failures are, more often than not, the proximate cause of them.
The third defect source is unnecessary intervention. Even precision maintenance, executed without error, carries a tax. Every time a technician breaks containment — removes an inspection cover, pulls a bearing, disturbs a seal, disconnects a coupling — the equipment must be reassembled, realigned, and recommissioned. Each of those steps is an opportunity to introduce the defects described above, even at magnitudes that defy detection while still carrying consequences.
But there is a subtler version of this problem that has no name and leaves no fingerprints: equipment that was operating within acceptable parameters before the work, and performs marginally worse afterward, with no identifiable cause. Vibration signatures shift slightly. Seal leak rates increase. Mean time between failures shortens. Nobody can point to what changed, because nothing changed that anyone can measure — the equipment was simply opened, and something that had settled into equilibrium over thousands of operating hours was reset.
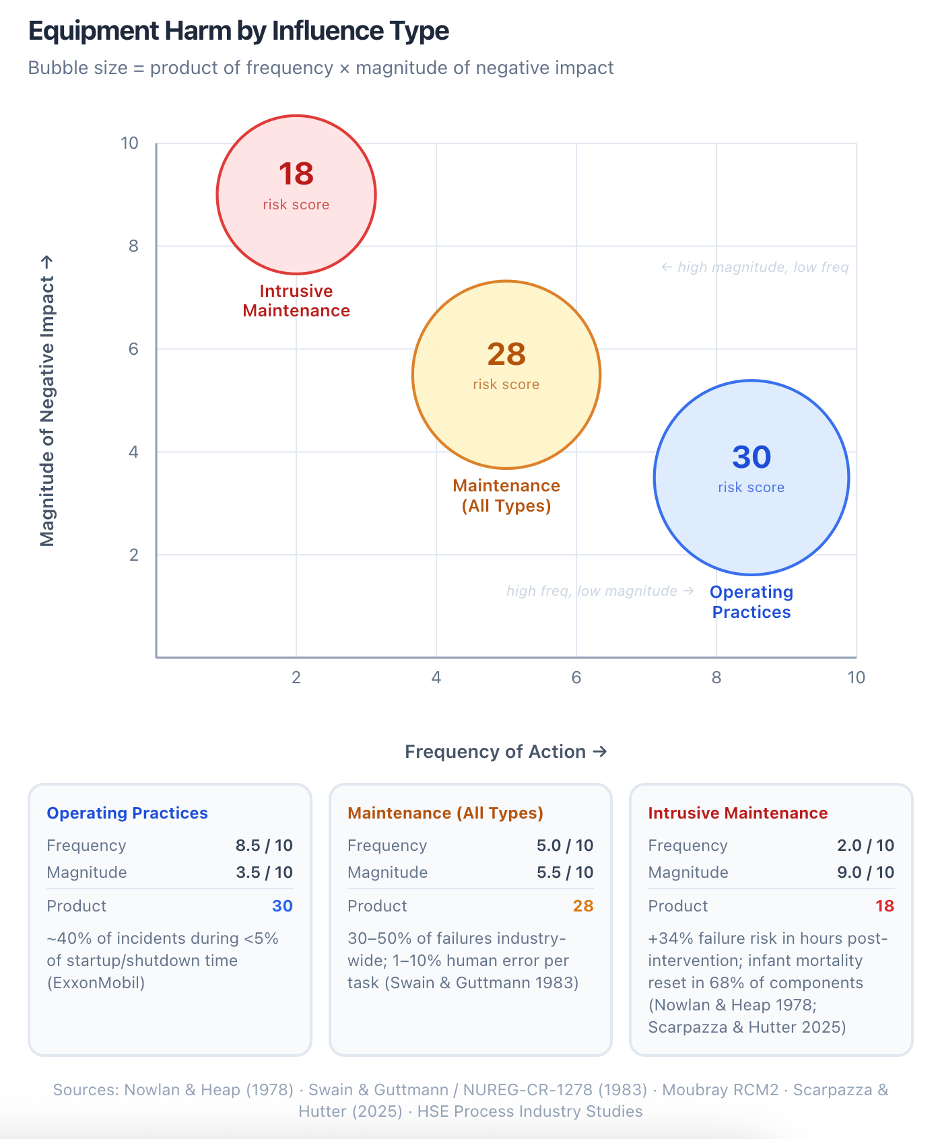
Intrusive maintenance scheduled against a calendar, rather than against a demonstrated need, does not merely risk error. It guarantees that the equipment will be exposed to all three defect sources — handling, reassembly, and disturbance — on a predictable schedule, regardless of whether any failure mode was actually developing.
If your maintenance program is reliably introducing defects on every fourth repair, no amount of condition monitoring will improve your equipment reliability. You are filling a bucket with the drain open.
Repairs That Do Not Restore
Go back to August in the life of P-1105A. The drive-end bearing has failed. Two technicians, Mike and James, bring the pump to the maintenance shop. They disassemble it on a workbench near the shop’s grinding area. Metallic dust from the grinder is visible on the bench surface. Neither technician wipes down the bench or covers the exposed bearing journals.
Mike retrieves the replacement bearing from the storeroom. It has been sitting on an open shelf in a humid Gulf Coast warehouse for fourteen months, in a box showing minor water staining from a roof leak two months prior. He does not look the bearing over or spin it by hand to verify smooth operation.
Mike installs the new bearing by pressing it onto the shaft using a length of steel pipe as an installation sleeve. The OEM procedure — filed in a cabinet in the site library, not referenced on the work order — specifies an induction heater to avoid applying axial force through the rolling elements. James had asked the shop supervisor to purchase an induction heater after a consultant gave training at the site a few years ago. Nothing ever happened. The pipe method transmits press-fit force directly through the balls, creating brinelling: microscopic dents in the raceways that will serve as initiation sites for spalling. The bearing is new. Its operating life is already compromised.
James reassembles the bearing housing and torques the bolts by feel. He learned about proper torquing specifications in tech school, but when he got his job at the refinery, no one was using them. He assumed it was one of those things you learn in school that is overkill in the real world. Two of the eight bolts are undertorqued by approximately thirty percent. Over time and thermal cycles, these weak points will be among the first places damage propagates.
The team conducts a laser alignment. Mike and James are proud to have gotten it dead on. They shimmed it with the same stack of ten reused, corroded shims. The service is around 350°F. There are no thermal growth corrections specified in the work order.
The work order completion notes: “Replaced DE bearing. Pump back in service.”
The pump left the shop in worse condition than its design intended.
This is not a story about bad mechanics. Mike and James are competent technicians doing their best with what they were given. The work order contained no installation specifications, no required tolerances, no acceptance criteria, and no reference to the OEM procedure. The system produced the outcome.
The Five-Micron Miracle
To understand why maintenance-induced defects are so destructive, you need to understand one fact about how rotating equipment works. The oil film that separates the rolling elements in a bearing from the raceway surface is, at operating conditions, approximately five microns thick. Five millionths of a meter. The oil film in a properly installed, properly lubricated bearing running at design load and speed is thinner than a human red blood cell.
This film is what enables machinery to run. When it is intact, bearing life is theoretically unlimited — the rolling elements never contact the raceway in a metal-to-metal sense. When it is compromised, bearing life collapses from years to months. And it is compromised by conditions that maintenance work routinely introduces:
● Looseness from undertorqued fasteners, which increases dynamic loads and cycles the film beyond its capacity to recover.
● Misalignment, which adds a persistent directional force that loads one side of the bearing disproportionately, creating a zone where the film is thinnest and particles are most damaging.
● Imbalance, which imposes a rotating force vector that sweeps the entire bearing circumference once per revolution and accelerates fatigue in the loaded zone proportional to the square of shaft speed.
● Particle contamination, which introduces abrasive material into the film in concentrations that reduce bearing life by 50 to 80 percent depending on particle size and ISO cleanliness code.
● Water contamination, which reduces the film’s pressure-viscosity properties, further thinning it under already-increased loads.
Five mechanisms. Four of them introduced, in part or in full, by the maintenance event that was supposed to restore reliability. This is exactly what happened to P-1105A. Bearing installed with a pipe instead of an induction heater — brinelling on the inner race, stress risers in the raceway. Housing bolts torqued by feel — looseness that increased dynamic loads. Alignment performed on reused, corroded shims without thermal growth corrections — a persistent radial force vector loading one side of the bearing for the pump’s entire next operating cycle. Work completed on a bench next to an active grinding operation — particulate contamination introduced at assembly, along with moisture-compromised oil from improper storage. Four defects. One repair. The work order said: “Replace bearings. Return to service.”
The bearing that could have run for years failed in four months. The system did not require installation specifications at the point of work. It did not define what precision looked like, how it should be measured, or what should happen when it was not achieved. If you asked anyone in the shop whether torque wrenches and induction heaters were available, you would get a look that tells you no one has mentioned those in a very long time, if at all. There was no clean preparation area in the shop for precision rebuilds. You cannot get these things right reliably without an operating system that makes them standard.
The Maintenance Execution Framework
Every failure pathway in the P-1105A repair had a known countermeasure. Not a new CMMS. Not a culture initiative. Not another RCM engagement. An execution reference — the artifact that connects engineering intent to field action — and the operating system conditions that make it usable.
That operating system has seven enabling conditions:
· The execution reference itself
· Proper tools to perform professional work
· On-spec materials and fluids
· Equipment access
· Continuity: protection from interruption during critical tasks
· Verified safe restart procedure,
· Learning by doing that improves the system with every finding.
When any one is absent, the system has disabled correct execution before the technician arrives. The Maintenance Execution Framework is what determines whether a repair restores the equipment or simply closes the work order.
The maintenance and reliability advice industry has spent four decades helping organizations analyze what to do. Almost none of it has addressed how to ensure it gets done at the level of precision the equipment requires. The failure modes are known. The tolerances are published. The OEM specifications exist. The only remaining question is whether the system delivers them to the technician at the moment of action — or leaves them in a binder in the site library that no work order has ever referenced.
A technician standing at P-1105 with a work order that says “PM pump. Check oil” and a technician standing there with a structured execution reference containing installation specifications, acceptance criteria, and failure history are not performing the same task. They are working in different systems. The first produces compliance. The second produces reliability.
The full argument — including the complete before-and-after execution reference for P-1105, the four prevention principles, and the 90-day implementation blueprint — is in The Maintenance Execution Gap: An Asset Management Operating System for World-Class Reliability, available in March.