
Your PM Schedule is a Conveyer of Empty Boxes
By Peter J. Munson
The maintenance and reliability industry has spent four decades chasing improvement in two systems. Both of them work. Neither of them, separately or together, determines whether the equipment actually gets maintained correctly. The fact that this is simultaneously obvious and unaddressed tells you more about the industry than any benchmarking study ever will.
The Two Engines
The first engine is Reliability Strategy: RCM analysis, failure mode libraries, P-F interval curves, condition monitoring program design, PM optimization. It answers what should be maintained and how. The industry has invested heavily in this engine, and the consulting ecosystem that surrounds it is enormous. We argue that the engine can be far more effective and is not where you need to be investing your money, but it is doubtless required.
The second engine is Work Management: planning, scheduling, backlog control, PM compliance tracking, resource leveling. It answers how work gets organized and delivered efficiently. This is the conveyor belt — the system that takes the work defined in the strategy and moves it, in the right order, to the right shop, at the right time. Lean maintenance, schedule compliance, wrench time studies — decades of optimization live here. Also required.
Both are necessary, but insufficient to fix what ails you.
If you attend any reliability conference in America this year, or read any of the trade publications, or sit through any vendor pitch, the conversation will be about one of these two engines. The strategy people will tell you to do more analysis. The work management people will tell you to schedule tighter and track compliance harder. The AI vendors — and there are a lot of them now — will tell you they can do both, faster. The conference circuit has been running this play since the early 1990s, with a little gloss and tech touching up and the same essential message.
Building the cargo to go in the boxes is mundane, does not provide consulting margin, and generally is beyond the capability of the career consultants who have never really worked in the industry. Do not waste money on anything else until you have those boxes filled.
The Cargo Problem
Think of Reliability Strategy as the system that creates labels for boxes of work: "Quarterly Pump PM," "Annual Seal Inspection," "Bearing Condition Check." Each label carries a scope and an interval. Think of Work Management as the production line that sorts those boxes, puts them on a conveyor, and delivers them — in order, on time — to the right shop.
Now picture the technician standing at the end of the conveyor. She picks up the box. She opens it.
The box is empty.

The work order says "PM pump. Check oil. Sample if needed." That is the entire instruction set for maintaining a centrifugal pump handling light naphtha at 140°F — a pump whose mechanical seal failure shuts a crude unit within the hour, whose bearing housing depends on oil-mist lubrication meeting specific cleanliness targets that nobody has specified anywhere. I have pulled these work orders at real plants, on real critical equipment, and the pattern is so consistent it has stopped surprising me. The strategy engine created a label. The work management engine delivered it on schedule. The technician received a box with nothing actionable inside.
What happens next is predictable: the technician fills in the gap from memory, from habit, from whatever the last person showed her on a Tuesday afternoon three years ago. If she is experienced and careful, the result is adequate most of the time. If she is new, or rushed, or tired, or if the job is one she does infrequently enough that the procedural details have decayed — and the behavioral science on skill retention says that half of training-acquired procedural knowledge is gone within six months — the result is a miss on an inspection or a defect on an action.
More than half of equipment that fails prematurely does so following maintenance work. The equipment did not arrive sick; the maintenance process made it sick. The industry calls this infant mortality, but the term is misleading in a way that lets the system off the hook — it implies something intrinsic to the equipment rather than something inflicted by the process.
Two mechanisms are doing the damage, and most reliability programs are designed to address neither one. First, defects introduced during work — bearings installed incorrectly, fasteners under-torqued, oil contaminated in storage and transfer, pumps misaligned after overhaul, operations running equipment off its best efficiency point against closed discharge valves. Second, defects that go undetected because PMs are designed to confirm compliance rather than detect condition — inspection language like "check," "inspect," "monitor" with no defined acceptance criteria, no quantitative threshold, no conditional escalation logic. The technician is expected to know what "acceptable" looks like from experience. The work order does not tell him.
The common cause behind both mechanisms is the same: no system exists to govern what happens at the point of execution.
Why the Industry Has Not Fixed This
The reason the gap persists is structural, and once you see it, you cannot unsee it.
The data systems, analytical frameworks, and vendor ecosystem that drive organizational investment decisions are architecturally biased toward what they can measure. Failure data is visible. Mean time between failure is visible. PM compliance percentages are visible. Prevention — true prevention of defects at the point of work, as distinct from "preventive maintenance" — is invisible. A perfectly executed bearing installation generates no data point. A contamination control program that shifts the entire reliability distribution leftward produces no dramatic event that justifies a conference presentation.
The result is a self-reinforcing cycle: defects are introduced during maintenance through imprecise execution; those defects produce degradation signatures that condition monitoring systems eventually detect; the detection triggers a work order, generating data; predictive models train on that data and recommend more monitoring and earlier detection; investment flows to monitoring infrastructure because the recommendations are data-backed and the ROI is calculable; the defects continue to be introduced at the next maintenance intervention because nothing in the cycle addresses execution quality. Each iteration makes the blind spot harder to see. The AI does not recommend plugging the sieve; it recommends predicting the next hole in the sieve.
And there is a $10 billion industry in the United States living off your challenges, almost all of it oriented toward the wrong end of the problem. That industry is now telling you to do the same things, quicker, with AI. The volume of slop will be overwhelming.
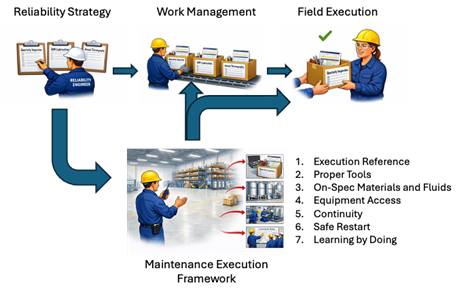
Filling the Boxes: The Maintenance Execution Framework
The Maintenance Execution Framework is the system that determines how work is performed, with what precision, under what controls, and with what feedback — the element that the advice industry has been missing. It sits between the two engines and fills the boxes with seven enabling conditions that, together, are exhaustive. Every PM-induced or PM-missed failure traces to one or more of these gaps. When any single enabler is absent, the system has disabled correct execution before the technician arrives.
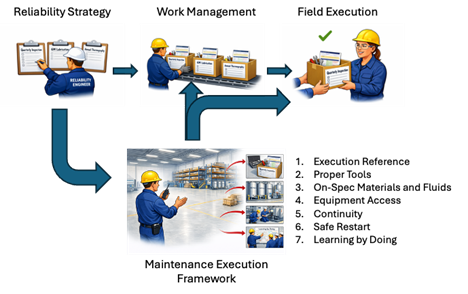
The Execution Reference is the visible artifact — actionable, structured guidance at the point of work, with acceptance criteria, conditional logic, failure history priming, and quantitative thresholds. Not a generic task list reproduced from a 1990s PM template, but a document that tells the technician what to look for, what an acceptable result looks like as a number, and what to do — with a timeline — when the result falls outside the band. The difference between "check bearing" and "bearing housing temperature: current acceptance band 125–145°F; if today's reading exceeds 145°F or exceeds any prior round reading by more than 3°F, generate a notification and call the maintenance supervisor" is the difference between a compliance exercise and a detection system. One of those produces findings; the other produces checkmarks.
Proper Tools means the precision instruments the job requires are stocked and maintained as standard issue, not special request. I have watched a reliability engineer build a technically perfect Execution Reference — correct bearing part number, induction heater requirement, torque specification in a star pattern at three passes to 45 ft-lbs, ISO cleanliness code for the oil — only to have the technician arrive at the tool crib and discover there was no induction heater. The request had been submitted, reviewed, approved in principle, deferred for budget review, and not acted on. The technician pressed the bearing onto the shaft with the same steel pipe he had used last time. The Execution Reference was complete; the execution was not. Your technicians are building and repairing project cars on the weekend with these tools, but they do not have them during their professional day job working on your process-critical equipment. We should not have to talk about this.
On-Spec Materials and Fluids means procurement specification by class, receiving inspection that checks something other than the packing slip, storage controls that keep bearings clean and dry and lubricants contamination-controlled, and point-of-use verification at the technician level. Most plants discover, the first time they walk the lube room with a Reference in hand, that the oil they are putting into a precision bearing housing is dirtier than the oil they are draining out. An oil cleanliness requirement of 17/15/12 per ISO 4406 is unenforceable if the storeroom stores lubricant in bulk drums with open bungs and irrelevant if drums are stored upright where water seeps into even a closed bung.
Equipment Access means proper isolation, decontamination, and the correct operational condition at time of inspection — not as administrative formalities negotiated the morning of the work, but as prerequisites integrated into the maintenance schedule. When operations turns equipment over for maintenance, the operator-side history — trends, abnormals, concerns — is part of the work package. When maintenance turns equipment back, the as-found condition, corrective action, and new baseline are part of the restart package. The handover goes in both directions or it goes nowhere.
Continuity means protection from interruption during critical work. A bearing installation split across shifts, a seal replacement where the second crew has to reconstruct the first crew's mental model from notes on a clipboard — these are not scheduling inconveniences. A schedule that treats bearing installation as interchangeable work units to be handed off at shift change has already chosen defect introduction as its operating policy. The decision was made in the scheduling office, not at the bench.
Safe Restart means a verified-stable observation window after every intervention — the work order does not close until both the maintenance superintendent and the operating supervisor sign off on documented, on-baseline readings. The window catches the maintenance-induced fault before it propagates into a process event. Operations leadership will push back: "We can't hold the work order open for hours after maintenance is done." The response is direct — production already paid for the maintenance window, and the verified-stable period is not additional downtime; it is the part of the maintenance window in which the asset is running and you are confirming the work was clean.
Learning by Doing means the findings from every execution cycle — what was found, what was out of spec, what was deferred and why — flow back into the Execution Reference for the next cycle. The Reference improves by running. The strategy gets smarter every time it executes. This is structurally different from the analyze-then-deploy sequence it replaces; discovery happens in execution data after deployment, not in workshops before it.
The Test
Every time you start thinking, "This is obvious," ask yourself: do we have this systemically solved at my plant? In the areas where things are going well, is it the system producing the result — or is it one outstanding supervisor or reliability engineer making it happen personally? Will the result hold when that person takes a different job?
I have not seen a plant in the last decade, across many dozens of plants from major corporations, that has these seven enablers solved systemically. The plants are not stupid; the people running them are not lazy. They are focused on the wrong answers because a $10 billion advice industry has been pointing them at the wrong answers for decades, and the data systems that inform their investment decisions are structurally incapable of making the case for the work that would actually move the needle.
I have been part of some of those wrong-answer projects myself. I have helped produce technically sound deliverables which were filed and never converted into anything a technician could use at the point of action. The industry's sequencing error — analyze exhaustively, then hope the translation to the field somehow happens — is one I participated in before I understood the missing element.
The boxes arrive at the technician pre-loaded with everything required for reliable execution, or they arrive empty. The two engines — strategy and work management — are necessary and real, and the work that has gone into building them over four decades was not wasted. But the engines are infrastructure for a cargo that most plants have never loaded. The Maintenance Execution Framework is how you fill the boxes. Everything upstream of that — every FMEA, every RCM study, every condition monitoring contract, every scheduling optimization — is preliminary work for a delivery that has not yet occurred.
The only remaining question is whether you fill them or keep running the conveyor empty.