
Problem Pumps: Deploy, Learn, Modify
In a previous post I presented a curve that describes the uniqueness of your assets: the idea that 80 to 90 percent of your equipment sits in a territory where the failure modes are already documented, the mitigations are already published, and the right answer is to compile and deploy equipment strategies, not analyze and re-derive.
The assets on the tail of the curve are the truly unique assets that have not had a FMEA for their circumstances, possibly ever: proprietary equipment, R&D line systems, etc.
This is different than a common asset in a difficult service. Every plant has these. They don’t need to be a science project: deploy known best practice and start learning from the data to apply very focused and abbreviated RCA to what is causing failures. Putting a lot of effort into FMEA up front is not the answer.
Let’s look at an example: a vertical centrifugal pump in a sump service — not particularly exotic.
What the FMEA Would Have Produced
A comprehensive FMEA for this pump and its motor driver touches nearly twenty distinct component types: impeller, wear rings, mechanical seal, rolling element bearings, shaft, coupling, volute housing, casing, bearing housing, O-rings, gaskets, shaft key, plus the motor’s windings, stator, rotor, cooling fan, terminal blocks, and motor housing. A typical failure mode library documents roughly a hundred unique part–failure mode combinations across those components. The pump side alone accounts for 74: eight bearing failure modes (abrasive wear, adhesive wear, complete failure, corrosion, damage, fatigue, looseness, misalignment), nine casing failure modes, seven each for the impeller and volute housing, six for the mechanical seal and wear rings, and so on through the coupling, shaft key, gaskets, and on. The motor adds another 27, dominated by seven winding failure modes and supplemented by stator, rotor, fan, terminal block, and housing degradation patterns.
One recent FMEA effort spent weeks generating such an output for each asset: a table with a hundred-odd rows, each with a failure mechanism, a severity score, an occurrence score, a detection score, and a risk-prioritization number.
FMEA is a seemingly rigorous process with a seemingly substantive quantitative output. It is not. Across many studies, researchers have found FMEAs and similar methodologies to be extremely inconsistent. Some of the studies’ findings:
· A study of nearly 200 experts rating the same failure modes found that individual failure modes received the full range of possible scores (1–10 for occurrence) and were simultaneously ranked as both the highest and least risky by different respondents.
· Expert-ranked top-10 failure modes showed zero overlap with actual incident database frequencies
· 41% of real incidents from one study involved failure modes an FMEA team never identified
· Two FMEA teams evaluating the same process had total RPN results that were off by a factor of four and found only 17 failure modes in common
FMEAs are a very imprecise instrument to begin with – and that is before we get down to what they really provide in terms of helpful prescription.
In the case of our pump system, FMEA suggests 15 “task families” that cover the various failure modes. After you’ve paid for a consulting team to do this… I can tell you that the vast majority of plants are going to reject some of these task families on sight – as they should.
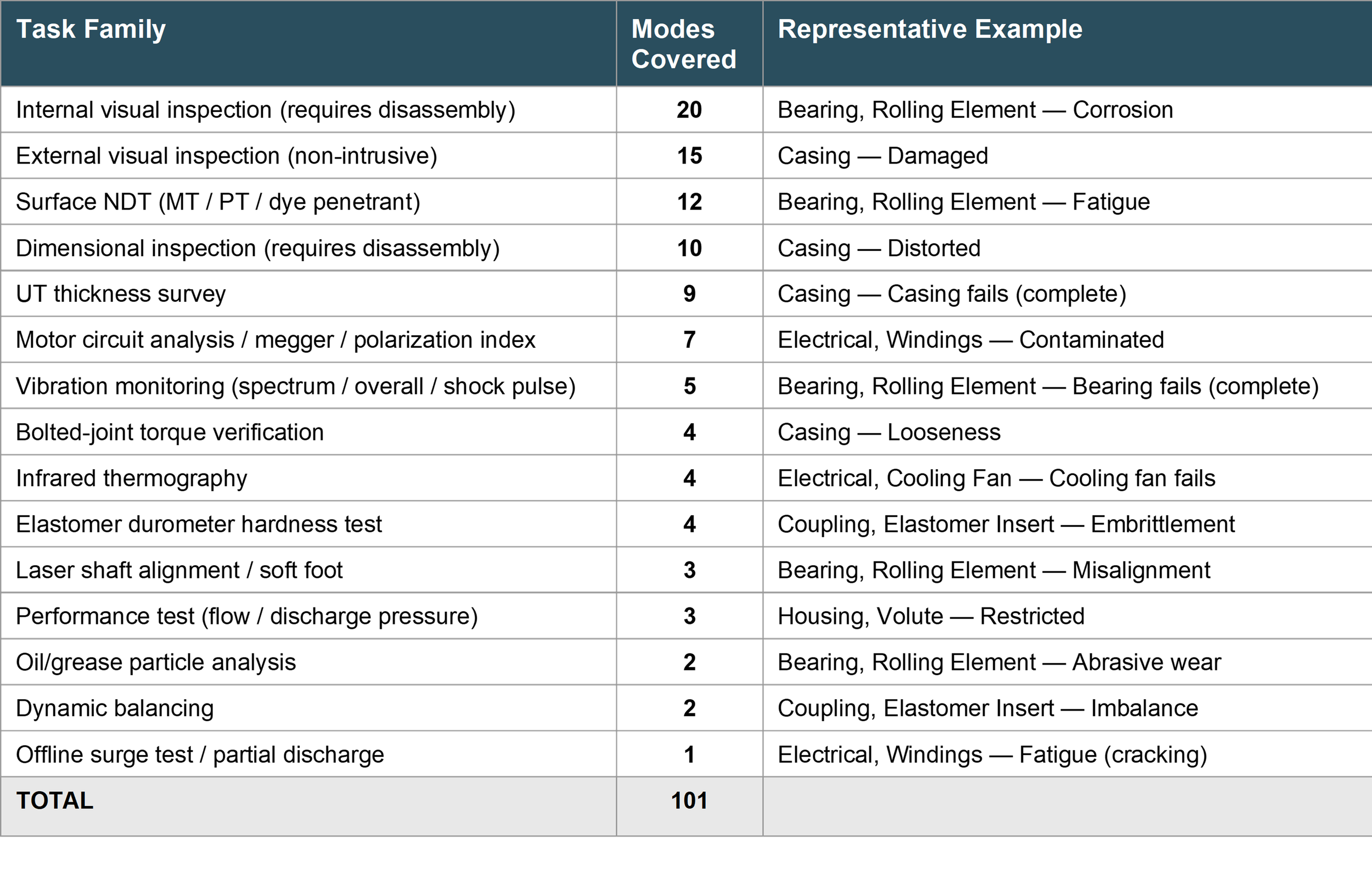
When you get down to what a plant can and should implement on all but the most astronomically critical/risky equipment, you throw out NDT, UT, dynamic balancing, surge test, and any teardown work. You’re left with a quarterly vibration, thermography, and visual inspection. Lubrication based on configuration and service. And ideally an annual online/offline inspection that includes alignment and fastener checks, coupling check, performance evaluation from available online data, etc.
Let me say that in a different way: for the vast majority of equipment, FMEA is an exercise in imprecise time wasting that results in prescriptions no plant will implement.
In contrast, if you skip FMEA and just apply known best practice preventive tasks for the equipment, you can cover over three-quarters of the failure modes an FMEA will (re-)identify. None of the uncovered failure modes are the ones that actually drive pump failure in real service.
What the Standard Deployment Looks Like
Instead of starting with FMEA workshops, we start with what the industry knows.
A Goulds 3171MT is a submerged wet-pit design with a mechanical seal and a single-stage impeller on a vertical shaft. The failure modes — bearing wear, sealing arrangement degradation, wear ring clearance opening, impeller erosion, coupling misalignment, etc. — are covered in OEM guidance, applicable API and HI practice, and every senior mechanic’s mental model. They have not changed since the pump was installed.
The standard PM strategy for a vertical sump pump is not a mystery. It looks like this:
Quarterly (running, non-intrusive): Grease the motor and pump bearings per OEM specification and interval. For a 3,500 RPM vertical pump on grease lubrication, the OEM interval is typically 2,000 hours, which aligns with quarterly execution. Take bearing temperatures with a contact pyrometer or IR gun at the motor DE and NDE housings: ≤180°F is acceptable, 180–200°F generates a notification with vibration follow-up within seven days, >200°F is urgent and requires evaluation for shutdown. Walk the sealing arrangement — packed box or mechanical seal, as fitted — and log its condition against a three-state criterion: dry or trace weepage is acceptable, steady drip generates a notification, spray or stream is an urgent corrective. Check the coupling guard is in place and secure. If there’s a flush system, verify flow is present and strainer differential pressure is within limits.
Read discharge pressure at a stable operating condition and compare it against the expected point on the pump curve — a $200 gauge on the above-grade discharge piping, logged by the operator on a monthly round, gives 60 to 90 days of warning on wear ring clearance opening, impeller erosion, and suction path restriction before functional failure, and does it without opening the pump.
Annual (minimally intrusive, LOTO required): Remove the coupling guard per safe work practice, check soft foot, measure angular and parallel offset — API 686 tolerance for this size class is ≤0.003” parallel and ≤0.001 in/in angular. Some people will say, “Why would I verify alignment every year?” My first answer is, “Sins of the past.” This is a great opportunity to clean up the sorts of installation errors that caused a catastrophic failure of the coupling on this pump during rainy season. Once your alignments are cleaned up, you can evaluate which pumps are more likely to walk over the course of a year — generally high energy pumps, hot services, etc. Inspect the coupling element for cracks, hardening, or set screw looseness. Assess bearing condition with shock pulse or vibration spectrum against a documented baseline. Inspect the mechanical seal gland externally and verify flush system pressure, temperature, and flow are within the OEM’s specified operating window.
Total annual labor: about 4.2 hours across four executions — three quarterly and an annual. The acceptance criteria come from the OEM manual, site standards, and applicable API/HI guidance. The inspection methods are standard. This is the compiled answer for a vertical sump pump in typical service, and it deploys in a day from a standard template.
The upload template to your CMMS should have the four executions — not 5. It should have three quarterly events and an annual that subsumes the quarterly requirements so you don’t make two trips, weeks apart. Your annual can do the greasing and online inspection before or after the offline inspection. The package should include an execution reference that specifies the inspection conditions, acceptance criteria, and actions to be taken if they are not met.
This does not need an FMEA. This should be on the shelf in upload ready detail from any provider that “does equipment strategies” or PM optimization. It is not. It is something that your team can do in a few hours with commercial AI support to accelerate and a human quality check.
Meet P-1369
P-1369 is storm water sump pump in a refinery coker unit. This installation has seen fifteen failure events since 2014. Nine months between failures, on average. The total corrective repair cost for this pump is more than 50 times the fleet median.
PM task lists were created for this pump during a long-forgotten PM optimization exercise over a decade ago. Those task lists languished in the ether because they were never properly configured with the SAP arcana to make them fire on schedule. Frustrating, but not uncommon. Thus, every work order in the record is corrective, on a nine-month cycle. Each event required the same 19-operation pull-and-rebuild sequence: electrician disconnect, blind and break piping, crane assist to pull the pump from the sump, decontamination, hydro blast, vac truck to clean coke fines from the sump, transport to vendor shop, 120 hours of shop time, reinstall, reconnect, run in.
Here is the part that matters: in 2024, after the pump failed again, the DCU unit and the pump shop sat down together, reviewed the pump condition jointly, and then rebuilt it identically to the previous twelve times — same cast iron wear rings, same cast iron impeller, same metallurgy that had been eroding on a 12-month cycle since installation. The pump failed again within twelve months.
That is what happens when an organization substitutes review for decision. They examined everything. They changed nothing.
The Curve Diagnosis: Where Does This Pump Actually Sit?
This pump is a common asset with common failure modes in a somewhat harsh service. Heart of the curve asset, tail of curve service. It just needs an adjustment for the service.
The primary failure mode — cast iron wear rings and impeller eroding in a dilute coke fines slurry — is not novel. Abrasive slurry service destroys cast iron internals on a predictable cycle. Goulds literature explicitly flags special bearing and material arrangements for abrasive solids service. The wear rings are found loose or severely worn on every opening, requiring 24 hours of machine work per rebuild. NDT inspection is called on every cycle: the damage is severe enough to warrant nondestructive testing of the casing and impeller each time. The mitigations are known. Any senior mechanic familiar with this pump class would have told you this on day one if anyone had asked.
The secondary failure mode — bearing flush lines plugging with the same coke fines that are destroying the pump internals, starving the bearings of clean flush fluid — is also not novel. It’s a documented consequence of flush plan selection in contaminated service. It showed up in the work order record explicitly: in January 2023, a work order was issued specifically to unplug the bearing flush tubing. Coke fines. When the flush is blocked, the bearings run in contaminated liquid, which accelerates the primary wear cycle.
The likelihood of an FMEA picking up this secondary failure mode cascade is low. The likelihood of the FMEA prescribing anything meaningful to mitigate this secondary failure mode cascade is even lower. Even if a team did nail this and recommend a design mitigation, the chance of that design mitigation happening in the absence of a painful string of failures is likewise very low.
The key learning here is that FMEA did not produce meaningful results for the heart of the curve asset and it did not prescribe meaningful mitigations for a heart of the curve asset in a tail service. Apply best practice and start learning.
What this pump has is an application problem that was never corrected: standard metallurgy in a service that requires abrasion-resistant materials... combined with over a decade of missed inspections that let the degradation cycle run unchecked every single year.
The fix is not a multi-week FMEA. It is a targeted root cause analysis and a set of engineering changes.
Design mitigation 1: Reduce abrasive loading at the source. Install a settling baffle or coarse screen upstream of the pump suction. The sump already accumulates coke fines — everyone knows they’re there, the vac truck crew cleans them out every time the pump comes out. A baffle that directs fines to a cleanout zone while the pump draws from cleaner water in the upper column reduces abrasive loading on every internal surface simultaneously. This is a fabrication job — a few thousand dollars in shop time. It addresses the root cause at the source rather than tolerating the abrasive loading and trying to survive it with better materials.
Design mitigation 2: Upgrade the wear components to match the actual service. Replace standard cast iron wear rings and impeller with hard-faced alternatives — Ni-Hard, tungsten carbide coating, or whatever the Goulds application engineer recommends for coke fines slurry in a 3171MT 1.5×2-8. The site has been coordinating with ITT Goulds on every rebuild for over a decade and has never once asked for upgraded material specifications. The cost of a set of hard-faced wear rings is likely less than a single 24-hour machining cycle — which happens every rebuild. This is a 15-minute phone call to the OEM application engineer, not a procurement odyssey.
Design mitigation 3: Upgrade the flush system to prevent secondary failure. The current bearing flush arrangement plugs with coke fines (documented in WO 84436281). A higher-flow flush configuration, a cyclone separator on the flush supply line, or at minimum a visual flow indicator (sight glass, ~$200) on the flush supply keeps the bearing environment clean and makes restriction visible before the bearings starve.
Longer-term consideration: A recessed impeller (vortex) pump handles solids without the impeller contacting the pumped fluid directly, yielding significantly lower wear rates in abrasive service at the cost of some hydraulic efficiency — which is immaterial on a storm water sump pump. Goulds and Flowserve both manufacture vortex pumps in compatible frame sizes. This is a capital decision for the next pump replacement cycle.
The combined implementation cost of the first three mitigations — baffle, material upgrade, flush improvement — is roughly $23,000 to $54,000. The 2024 single-event repair cost was $169,645. Every one of these recommendations pays for itself in a single avoided failure.
That is the RCA output. No workshop. No RPN matrix. No facilitated consensus exercise. The failure record told you what was failing. The OEM manual told you why. The engineering mitigations address the root cause — they change the conditions that produce the failure, rather than trying to detect the failure faster. The PM strategy is the standard deploy. The RCA is where the engineering judgment goes.
A Morning’s Work: Connecting Standard Deploy to RCA Output
The PM strategy and the engineering mitigations are separate workstreams, and it matters that they stay separate — because the PM strategy should already be running while the engineering changes are being specified, quoted, and scheduled.
Open the standard vertical sump pump PM template. It already has the baseline quarterly and annual tasks described above. That’s your starting point — and for P-1369, it should have been running since 2014.
Now apply the two targeted PM modifications that the RCA identified:
PM modification 1: The standard template already has “verify flush system flow” as a quarterly check. For this asset, that becomes a specific acceptance criterion: flow indicator present, no restriction detected. If the flush system sight glass from the engineering mitigations is installed, the check is a glance. If not, it’s a documented observation of flow at the existing connection point. Either way, it takes 30 seconds and it’s the difference between catching flush restriction before bearing damage and finding out when the pump seizes.
PM modification 2: Add discharge pressure trending to the monthly operator round. As wear rings open in abrasive service, the pump loses head — discharge pressure drops before functional failure. A $200 pressure gauge on the above-grade discharge piping provides an early performance trend. With a P-F interval of 60–90 days on wear ring degradation in this service, monthly reads give adequate warning to schedule a planned intervention instead of an emergency pump pull. That check takes 30 seconds and goes on whatever operator round already exists in the DCU.
The annual intrusive scope remains the standard template, with any additional checks added as operating experience accumulates.
The engineering action items are separate from the PM strategy and are pursued in parallel: settling baffle, hard-faced wear rings and impeller at the next rebuild, flush system improvement. Those are corrective engineering actions with their own MOC process and capital justification. They are not PM tasks.
Total annual PM labor investment: 4.20 hours across five executions. Average annual reactive repair cost when nothing was done: $56,028. The cheapest single failure event in the history of this pump — a blown coupling in March 2025 — cost $7,680 in emergency overtime and schedule disruption. That exceeds the full annual PM labor cost before you even get to the real number: the $25,000 to $170,000 it costs every time the pump comes out of the sump.
The current strategy — run-to-failure — is the most expensive option on the list. It has always been the most expensive option. The pump just kept failing because nobody made a different choice.
What This Example Illustrates
P-1369 is not proof that bad actors require elaborate analysis. It is proof of the opposite.
The failure mode was known and documented every time the pump came out of service. The equipment data confirmed that standard metallurgy was wrong for the application. The OEM makes versions of this pump — and alternative pump types — that handle the service. The PM task lists were built in 2014 and have been sitting in the system for eleven years. The bearing flush plugging was a documented work order event. Every piece of information needed to address this pump has existed for years.
What was missing was not knowledge. What was missing was the decision to act on it.
The methodology is straightforward:
1. Deploy the standard PM strategy for the equipment class. The quarterly and annual template is compiled from OEM guidance, applicable standards, and documented practice. It deploys in a day. It should have been running for years. This is not analysis — it is delivery of a known answer.
2. Run a focused RCA on the confirmed bad actor profile. Start from the CMMS failure history and shop findings. Identify the causal mechanism. For P-1369, the root cause is a material-service mismatch — standard metallurgy in abrasive service. The contributing causes are flush system vulnerability and absence of any fines exclusion at the sump.
3. Specify engineering mitigations that address the root cause. The mitigations for this pump are design changes — settling baffle, material upgrade, flush improvement — not PM frequency adjustments. The PM strategy was already correct; the problem was that the pump was ingesting material it was never designed to handle, and nobody changed the design.
4. Apply targeted PM modifications from the RCA findings. Two additions to the standard template: a specific flush verification criterion and a monthly discharge pressure trend. These are detection improvements for the specific failure modes confirmed by the RCA — they do not replace the engineering mitigations, they buy time while the engineering changes are implemented.
The curve tells you where to spend your engineering time. The standard deploy handles the vast center — and should have been running on this pump since 2014. The targeted RCA handles the known bad actor profile — and takes a morning once you commit to working from the failure record instead of deriving from first principles what the pump has already told you fifteen times.
The 28-year-old technician who pulls this pump out of the sump next April deserves to show up to an inspection with acceptance criteria, not questions. The standard deploy plus the RCA-driven modifications gives him that. Nothing in the FMEA process gives him anything the work order history didn’t already say.
Deploy the known answer. Run the RCA on confirmed bad actors. Specify engineering mitigations that change the conditions, not just the monitoring. Let the data tell you what you got wrong.
That’s the whole methodology. The pump doesn’t need more analysis. It needs someone to wire the task lists to the scheduling engine, call the Goulds application engineer about abrasion-resistant wear components, and get a settling baffle fabricated before the next April failure.